
3.1. General notes
These weeks are covering June 24th to July 4th. It covers 2 weeks as Hopper had assorted issues in running the benchmark that were only resolved in week 4. Additionally, due to the holiday and Yelp! trip(part of my REU program), I worked fewer days than normal.
3.2. Goals
The goals this week were to do the PROOF benchmark on HOPPPER, create a script that runs over histograms, producing printed files of them in gif or eps format, and then to research a timer for ROOT as to correctly measure the time needed in “real” time and CPU time. eps is preferred as it can easily be imported into laTex, unlike gif.
3.3. How to do the Proof Benchmark on Hopper
I followed the same procedure in terms of the macros as for PDSF, but many errors were encountered. Please see below.
3.4. Producing images from .root files
In order to simplify the processing of the produced ROOT histograms and variables, I created a macro which would plot all the histograms found within a particular .root file. It is attached below:
#include
#include
#include
using namespace std;
//macro2.c
void macro4(){
//this is the file you are using
TFile *fileL = new TFile("data/Level2_HESE_nugen_nue_IC86.2011.009250.000xxx_All.root");
fileL->cd();//cd to said file
//create a canvas to print it on
TCanvas *myCanvas = new TCanvas();
//access the Ttree that we know exists in there, from prior macros
TTree* MyTree;fileL->GetObject("Mreco",MyTree);
Int_t nevent = MyTree->GetNbranches();//get the branches
const char * tempName;//temp name of particular leaf
for (Int_t i=0;iGetListOfBranches()->UncheckedAt(i)->GetName(); //get the name
//print it on the canvas
myCanvas->cd();
MyTree->Draw(tempName);
//save it as a certain name
strcat(tempName,".eps");
myCanvas->SaveAs(tempName);
}}
3.5. Timer
There are two classes of timer for ROOT.
TTimer is explained at http://root.cern.ch/root/html/TTimer.html and works on eventloops, or loop of events. It stops events after a certain amount of time, which is useful for measuring walltime and simulating the actual shutoff done with Hopper.
TStopwatch is explained at http://root.cern.ch/root/html/TStopwatch.html and returns the real, and cpu time between start and stop events defined by user. This would be very good to show that PROOF is actually faster, in both real and CPU time, and will be used later on a physics analysis. It is used as shown in the following simple c script.
//proof2.c
void proof2(){
TStopwatch t;//create the timer object
t.Start();//start the timer
//your regular script goes here.
TProofBench pb("");
pb.MakeDataSet();
pb.RunDataSet();
t.Stop();//stop the timer
t.Print();//print info
}
3.6. Benchmark results
The following are the results of the benchmark on Hopper
Data IO benchmark

The data benchmark does not scale as expected, this is due to working out of the home directory and will be explained in detail in week 5 and in errors. Effectively, there is an IO bottleneck though.
CPU benchmark results
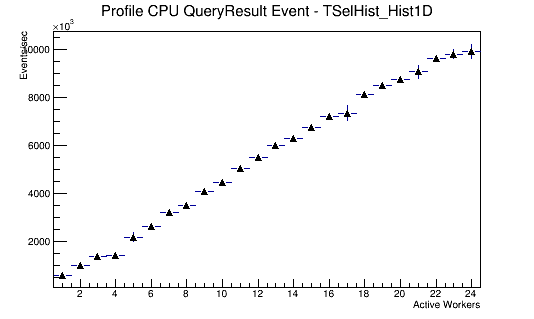
The CPU scales as expected.
3.7. Errors encountered
There are erorrs with PROOF running and producing data/the IO process on HOPPER, and using the home directory as the working one.
User not found error
In the event you get the following error, when you in fact, exist as an user id: amct: No such user, it is an error with bash on Hopper. I have changed my aprun line to be
aprun - n 1 -N 1 -d 24 -cc none sh /global/project/projectdirs/pdsf/amct/hopper/root/rootShell3.sh
and also tried removing the #PBS -V flag to possible improvement. This did not change anything and was eventually resolved by using the ccm linux and not the reduced version.
Strange results running out of home directory Sometimes, running the benchmarks on Hopper out of the home directory caused odd results. It would produce a data benchmark similar to the one below.
This doesn’t look like the expected scaling and has giant error bars. This is due to running it out of the home directory, which has strict bottlenecks for IO to discourage people from using it as a working directory. Find out where your scratch directories are by typing printenv|grep SCRATCH and consider running from each one to see different results
Error with libraries not found and compilation, path correct In the event of getting the following error after many lines saying various libraries/headers were missing,
g++: /global/u2/a/amct/.proof/packages/ProofBenchCPUSel/TSelHist\_cxx\_ACLiC\_dict.o: No such file or directory Error inACLiC
: Compilation failed!
It is suggested that you make sure that you don’t have multiple files running out of your working directory. Running two instances causes them to overwrite each other and have tons of issues, like this.
Error with finding home directory For the same reason as the user not found directory error, there was an error with finding my home directory. It was resolved by using the following as my .pbs script.
#PBS -q ccm_queue #PBS -l mppwidth=24 #PBS -l walltime=04:00:00 #PBS -N myscript #PBS -e myscript.$PBS_JOBID.err #PBS -o myscript.$PBS_JOBID.out cd $PBS_O_WORKDIR export CRAY_ROOTFS=DSL module load ccm module load openmpi_ccm ccmrun mpirun -np 1 /global/project/projectdirs/pdsf/amct/hopper/root/rootShell2.sh
The ccm_queue line refers to the queue to be used, there is a debug queue as on pdsf, but for ccm. CCM is the full linux module, which must be used in order to get functions like id correctly linking to the database. The modules for ccm must be loaded, and instead of using aprun, mpirun must be used, but it is used in a similar manner to aprun, calling your shell script which loads root with the macros. Qsub is still used to submit the script, and it is otherwise similar to the “normal” pbs script in the examples.
The shell script needs to then have the -l flag appended to the #!/bin/bash line at the top, as follows #!/bin/bash -l
This use of ccm may cause minor hits in efficiency, and we are determining if there is any way to resolve that without modifying the root source code. Specifically, the issue is that it takes up to an hour to load ccm, which seems excessive, but may be acceptable for longer running jobs.
We had additionally had attempted to fix it by appending our bashrc.ext to have umask 0027 added at the end. This did not seem to fix anything. It would change the default file permissions, for our bash files.
RSA errors You may encounter the following error when running ccm for the first time, if over quota in your home directory. You may, upon occasion, need to regenerate RSA keys as well.
Incomplete rsa keys - CCM might not function properly with some protocols. Please correct by running ssh-keygen
This was resolved by running ssh-keygen, but should be resolved properly by making sure your working directory is in the correct location, ie, not your home as to avoid going over quota. This is resolved by changing the PROOF sandbox, as shown in the following c++ macro.
#include
using namespace std;
//proof.c
void proof(){
//the following line changes the sandbox location.
gEnv->SetValue("ProofLite.Sandbox", "/location/of/sandbox");
//your other code is put below it.
TProofBench pb("");
pb.MakeDataSet();
pb.RunDataSet();
}
It should be noted that it is essential to change the location of the sandbox before starting proof.
Permission denied in cshell If you use cshell, the proper syntax for running a .csh file is not . thefile.csh, but ./thefile.csh even if in the same directory, etc. This differs from bash where the syntax generally is . bin/thisroot.sh in order to run your file to get ROOT working, for example.
Path errors It is strongly suggested to make sure your library path is correct, and that you have run . bin/thisroot.sh before starting root. For better coding practice, it could be added to your .sh script that you submit. This is the library path I use on Hopper.
export LD\_LIBRARY\_PATH=/global/project/projectdirs/pdsf/amct/hopper/root/lib/ :/common/nsg/sge/ge-8.1.2/lib/lx-amd64:/common/usg/lib/
Out of time errors It should be noted that there were many times when 2 hours was not long enough to run the benchmark. It may take longer to queue for a 6 hour long script, but it was the amount of time I found to suffice for all of the benchmarks to run. It takes longer on Hopper than on pdsf. I found that when using the scratch areas, even 6 hours was not enough.
3.6. Benchmark results
The following are the initial results of the benchmark on Hopper

The unexpected bumps are due to running the IO benchmark out of the home directory. Using a different directory had different results, as will be described later. The CPU scales nicely, regardless.

3.8. Hopper differences in output
Hopper had the most differences depending on the directory used for the sandbox, the differences were most pronounced for IO.
Hopper Home Directory Running jobs out of the home directory is highly discouraged. There is a strict bottleneck of 100MB/sec and a quota of 50GB. This is easily exceeded, but ROOT will attempt to use it by default, so it is important to be noted.
SCRATCH and SCRATCH 2 Scratch directories still have a bottleneck, that prevents IO of greater than 35GB/sec, but are encouraged for IO intensive jobs. The default quota is 5TB, which is unlikely to be exceeded in a reasonable run, but if it is, there is the global scratch option, and the quota can be increased upon request. Files left on the Scratch directories are purged after 12 weeks. The location of the scratch directories varies per user, but can be found via the variable $SCRATCH and $SCRATCH2. The CPU Benchmark is shown first, followed by the IO Benchmark. It shows an expected linear increase.


Global Scratch Global scratch includes reduced IO speeds of 15GB/sec, compared to user Scratch, but has a default quota of 20TB and allows users to run code on multiple platforms.
The IO Benchmark shows the largest differences and is shown below
.
3.8. Hopper differences in output
Hopper had the most differences depending on the directory used for the sandbox, the differences were most pronounced for IO.
Hopper Home Directory Running jobs out of the home directory is highly discouraged. There is a strict bottleneck of 100MB/sec and a quota of 50GB. This is easily exceeded, but ROOT will attempt to use it by default, so it is important to be noted.
SCRATCH and SCRATCH 2 Scratch directories still have a bottleneck, that prevents IO of greater than 35GB/sec, but are encouraged for IO intensive jobs. The default quota is 5TB, which is unlikely to be exceeded in a reasonable run, but if it is, there is the global scratch option, and the quota can be increased upon request. Files left on the Scratch directories are purged after 12 weeks. The location of the scratch directories varies per user, but can be found via the variable $SCRATCH and $SCRATCH2.
Global ScratchGlobal scratch includes reduced IO speeds of 15GB/sec, compared to user Scratch, but has a default quota of 20TB and allows users to run code on multiple platforms.
The deviations from linear are because of collisions with other threads on the GSCRATCH directory. There is a limited wirespeed and IO output, which must be shared between all users.
Hopper Project Directories.Hopper Project directories work the same way as PDSF project directories and are stored on the same global file system, thus enabling cross system and user jobs. IO is negatively impacted, as shown below.
Hopper Project Directories.Hopper Project directories work the same way as PDSF project directories and are stored on the same global file system, thus enabling cross system and user jobs.

3.7. Differences for PDSF output
PDSF has the most differences depending not on the sandbox directory, but on the queue used.These are described below. Images are contained within the final paper.
Regular Queue: On the regular PDSF queue, nodes are shared between users. This can cause overlapping and a small delay when multiple users are using the same node. The non Mendel nodes have 16 real cores, which with hyperthreading, results in 32 virtual cores. Mendel Nodes resulted in different results, which are presently being explored.
Debug Queue The debug queue sends jobs to the debug nodes, which have 8 cores for the exclusive use of a single job.
Drained Node Although draining a node is not usually done in a production job, it is an effective way to test a benchmark. It preserves exclusive access to one of the standard nodes, such as those in the regular queue, with 32 virtual cores. It provides an accurate scaleup of the debug queue results
How to get PDSF to output memory. Because PDSF does not automatically output the memory used, I used the command free, with flags -l and -g to output the amounts used in the shell script that was submitted. This allows one to determine, in GB, the amount of memory used.
